

Running Vulnerability Scans for Spark Third Party Packages


If you use Spark in your codebase, chances are you also use some popular third-party packages to work with Spark. What does this mean from a security perspective? Your application may have some security vulnerabilities introduced due to these third-party packages too. If you are looking to find vulnerabilities in these packages, sharing what I tried in the hope that it helps you out as I couldn’t find too many resources when researching for my specific use case.
1. Get the source repository of the third-party package that you want to assess. This can be found at https://spark-packages.org/.
As an example, let’s consider kafka-spark-consumer. The corresponding page of kafka-spark-consumer points you to the source repo.
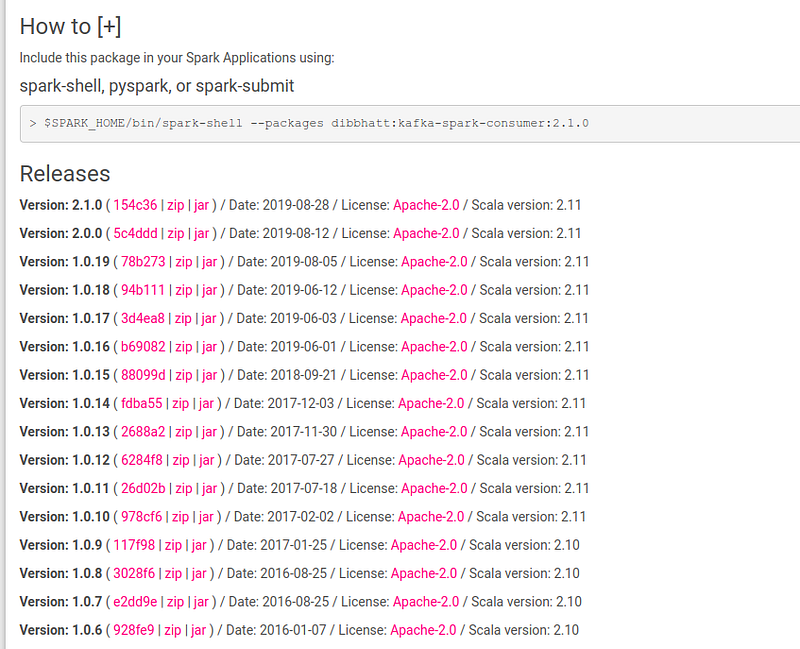
The commit hash of the versions would take you to the source code of the package.
2. I used Trivy for scanning security vulnerabilities. If Trivy isn’t installed already, install the same using
sudo snap install trivy
3. Once Trivy is installed, then use the Trivy command for scanning Git repositories and provide the URL we obtained from Step 1.
trivy repo https://github.com/dibbhatt/kafka-spark-consumer.git
Trivy traverses through relevant files and prints the list of potential vulnerabilities and their severity. It also shows the current version of the dependency packages and the version in which the security vulnerability may be potentially fixed, in case you are interested in upgrading the packages to fix the issues.
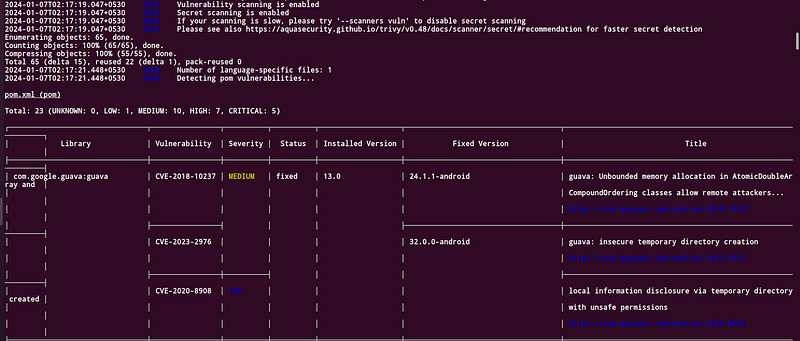
Please note that Trivy does the check by detecting a few language-specific files in the directory, for example, Pipfile.lock for Python, and then uses these files to scan the vulnerabilities in the dependencies. If these files are not present in the package, or the package is written in a language unsupported by Trivy, the result of the scan may not be accurate. In such cases, using alternative tools to Trivy would be the way to go.